# Install the necessary dependencies
import os
import sys
!{sys.executable} -m pip install --quiet pandas scikit-learn numpy matplotlib jupyterlab_myst ipython tensorflow_addons opencv-python requests
7. Stable Diffusion Model#
7.1. Overview#
Stable Diffusion is the most advanced model in the Diffusion model family. It employs a more stable, controllable, and efficient approach to generating high-quality images. There have been significant advancements in the quality, speed, and cost of image generation, allowing this model to generate images directly on consumer-grade GPUs, reaching at least 512512 pixel resolution. The latest XL version can generate controllable images at the level of 10241024 pixels, with a 30x improvement in generation efficiency compared to previous Diffusion models. Currently, Stable Diffusion’s applications are not limited to image generation but are also widely used in areas such as natural language processing, audio, and video generation.
Stable Diffusion can be applied in many fields. Below, I will guide you through its application in the field of text-to-image translation.

You can learn in detail how the Stable Diffusion model generates images through this video.
7.2. Components#
Stable Diffusion itself is not a single model but a system architecture composed of multiple modules and models. It consists of three core components, each of which is a neural network system, also known as the three fundamental models:
ClipText for text encoding. Input: text(prompt). Output: 77 token embeddings vectors, each in 768 dimensions.
UNet + Scheduler to gradually process/diffuse information in the information (latent) space. Input: text embeddings and a starting multi-dimensional array (structured lists of numbers, also called a tensor) made up of noise. Output: A processed information array
Autoencoder Decoder that paints the final image using the processed information array. Input: The processed information array (dimensions: (4,64,64)) Output: The resulting image (dimensions: (3, 512, 512) which are (red/green/blue, width, height))
7.3. Diffusion Explainer#
Through this project, let’s learn how Stable Diffusion transforms your text prompt into image!
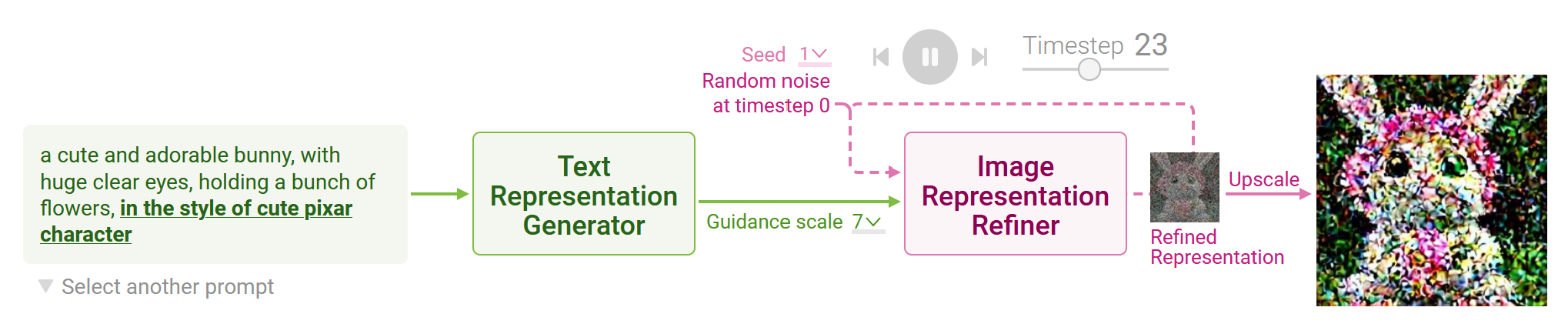
7.4. Text Representation Generation#
Clicking Text Representation Generation shows how a text prompt is converted into a text representation, a vector that summarizes the prompt. It consists of two steps: tokenizing and text encoding.
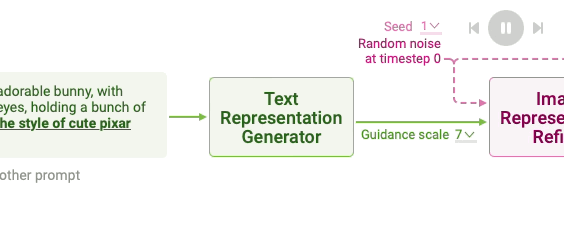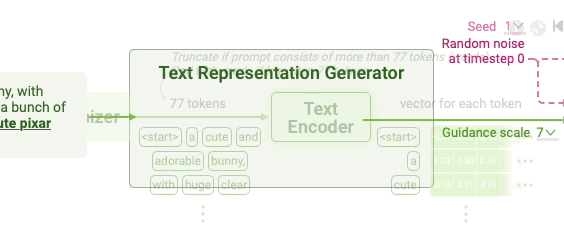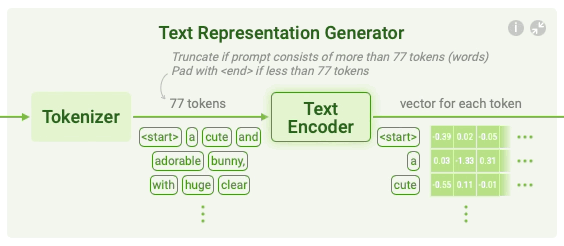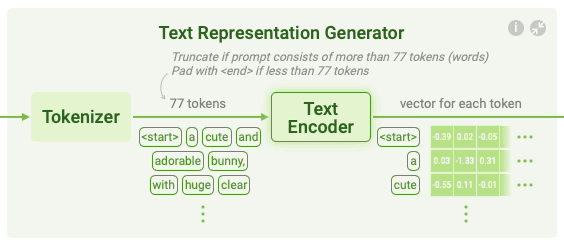
Tokenizing Tokenizing is a common way to handle text data to change the text into numbers and process them with neural networks.
Stable Diffusion tokenizes a text prompt into a sequence of tokens. For example, it splits the text prompt a cute and adorable bunny into the tokens a, cute, and, adorable, and bunny. Also, to mark the beginning and end of the prompt, Stable Diffusion adds start and end tokens at the beginning and the end of the tokens. The resulting token sequence for the above example would be start, a, cute, and, adorable, bunny, and end. For easier computation, Stable Diffusion keeps the token sequences of any text prompts to have the same length of 77 by padding or truncating. If the input prompt has fewer than 77 tokens, end tokens are added to the end of the sequence until it reaches 77 tokens. If the input prompt has more than 77 tokens, the first 77 tokens are retained and the rest are truncated. The length of 77 was set to balance performance and computational efficiency.
Text encoding Stable Diffusion converts the token sequence into a text representation. To use the text representation for guiding image generation, Stable Diffusion ensures that the text representation contains the information related to the image depicted in the prompt. This is done by using a special neural network called CLIP.
CLIP, which consists of an image encoder and a text encoder, is trained to encode an image and its text description into vectors that are similar to each other. Therefore, the text representation for a prompt computed by CLIP’s text encoder is likely to contain information about the images described in the prompt. You can display the visual explanations by clicking the Text Encoder above.
7.5. Image Representation Refining#
Stable Diffusion generates image representation, a vector that numerically summarizes a high-resolution image depicted in the text prompt. This is done by refining a randomly initialized noise over multiple timesteps to gradually improve the image quality and adherence to the prompt. You can change the initial random noise by adjusting the seed in Diffusion Explainer. Click Image Representation Refiner to visualize each refinement step, which involves noise prediction and removal.
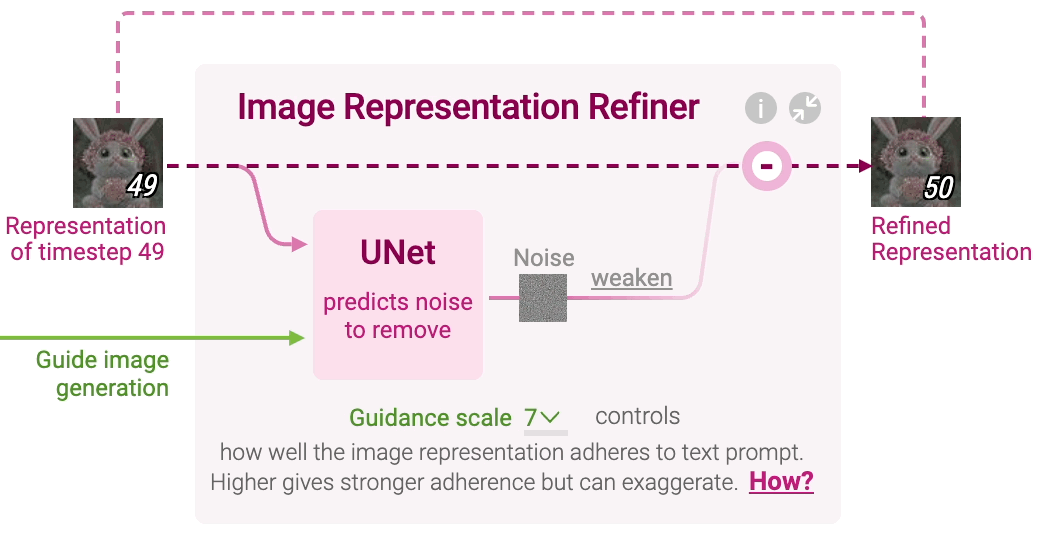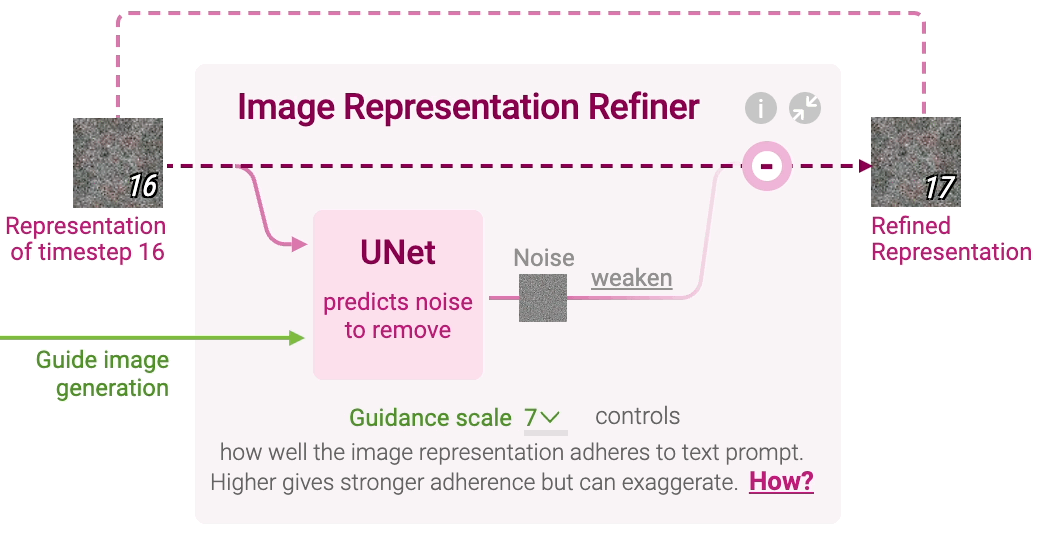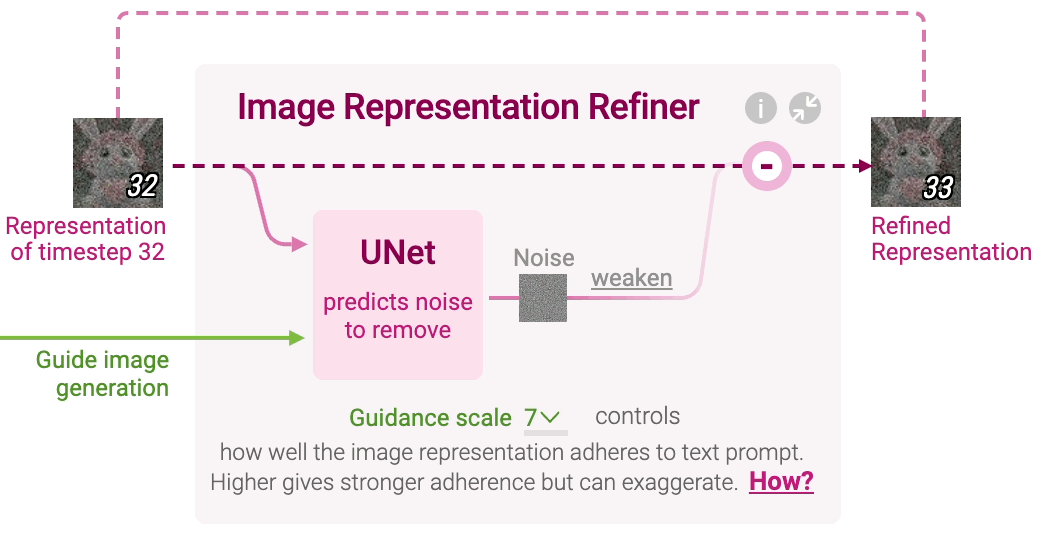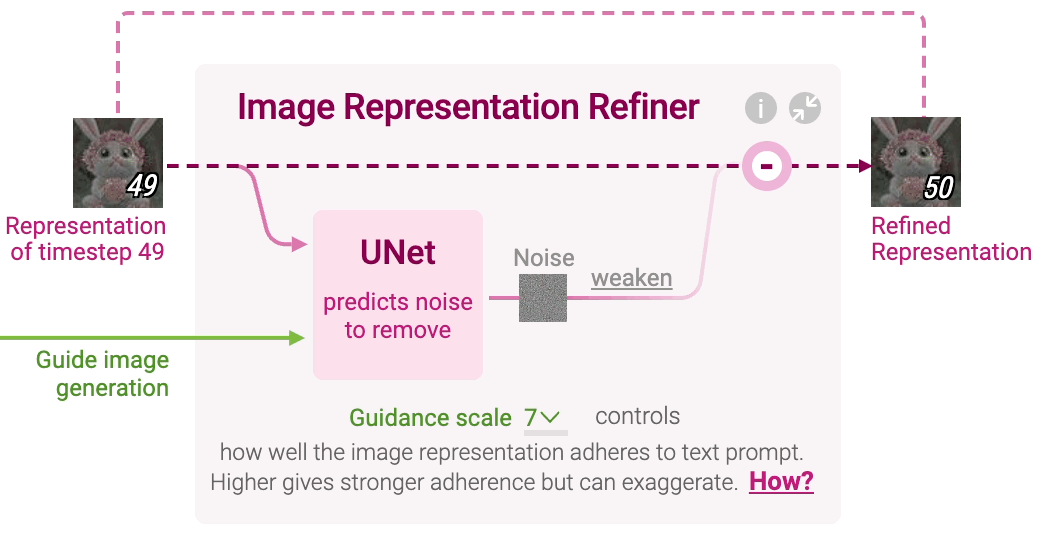
Noise Prediction At each timestep, a neural network called UNet predicts noise in the image representation of the current timestep. UNet takes three inputs:
Image representation of the current timestep Text representation of the prompt to guide what noise should be removed from the current image representation to generate an image adhering to the text prompt Timestep to indicate the amount of noise remaining in the current image representation
In other words, UNet predicts a prompt-conditioned noise in the current image representation under the guidance of the text prompt’s representation and timestep.
However, even though we condition the noise prediction with the text prompt, the generated image representation usually does not adhere strongly enough to the text prompt. To improve the adherence, Stable Diffusion measures the impact of the prompt by additionally predicting generic noise conditioned on an empty prompt (” “) and subtracting it from the prompt-conditioned noise:
impact of prompt = prompt-conditioned noise - generic noise
In other words, the generic noise contributes to better image quality, while the impact of the prompt contributes to the adherence to the prompt. The final noise is a weighted sum of them controlled by a value called guidance scale:
generic noise + guidance scale x impact of prompt
A guidance scale of 0 means no adherence to the text prompt, while a guidance scale of 1 means using the original prompt-conditioned noise. Larger guidance scales result in stronger adherence to the text prompt, while too large values can lower the image quality. Change the guidance scale value in Diffusion Explainer and see how it changes the generated images.
Noise Removal Stable Diffusion then decides how much of the predicted noise to actually remove from the image, as determined by an algorithm called scheduler. Removing small amounts of noise helps refine the image gradually and produce sharper images.
The scheduler makes this decision by accounting for the total number of timesteps. The downscaled noise is then subtracted from the image representation of the current timestep to obtain the refined representation, which becomes the image representation of the next timestep:
image representation of timestep t+1 = image representation of timestep t - downscaled noise
7.6. Image Upscaling#

After all denoising steps have been completed, Stable Diffusion uses a neural network called Decoder to upscale the image representation into a high-resolution image. The refined image representation fully denoised with the guidance of the text representations would result in a high-resolution image strongly adhering to the text prompt.
7.7. How do prompt keywords affect image generation?#
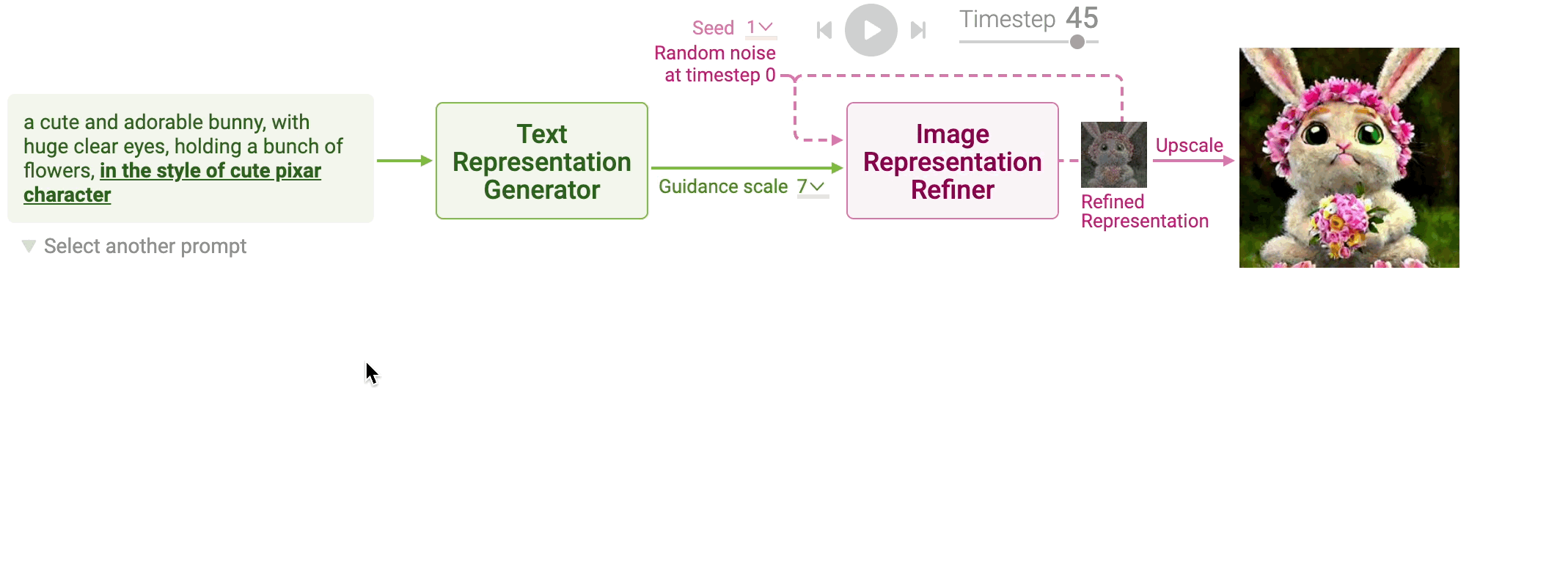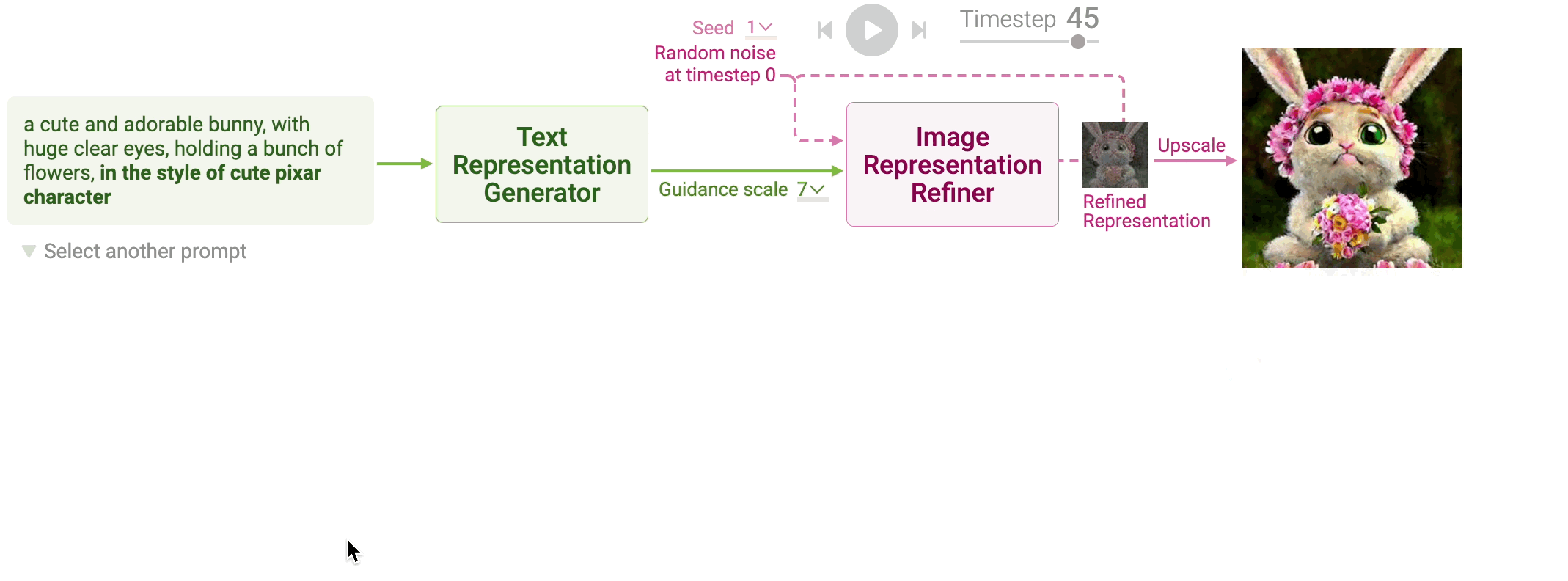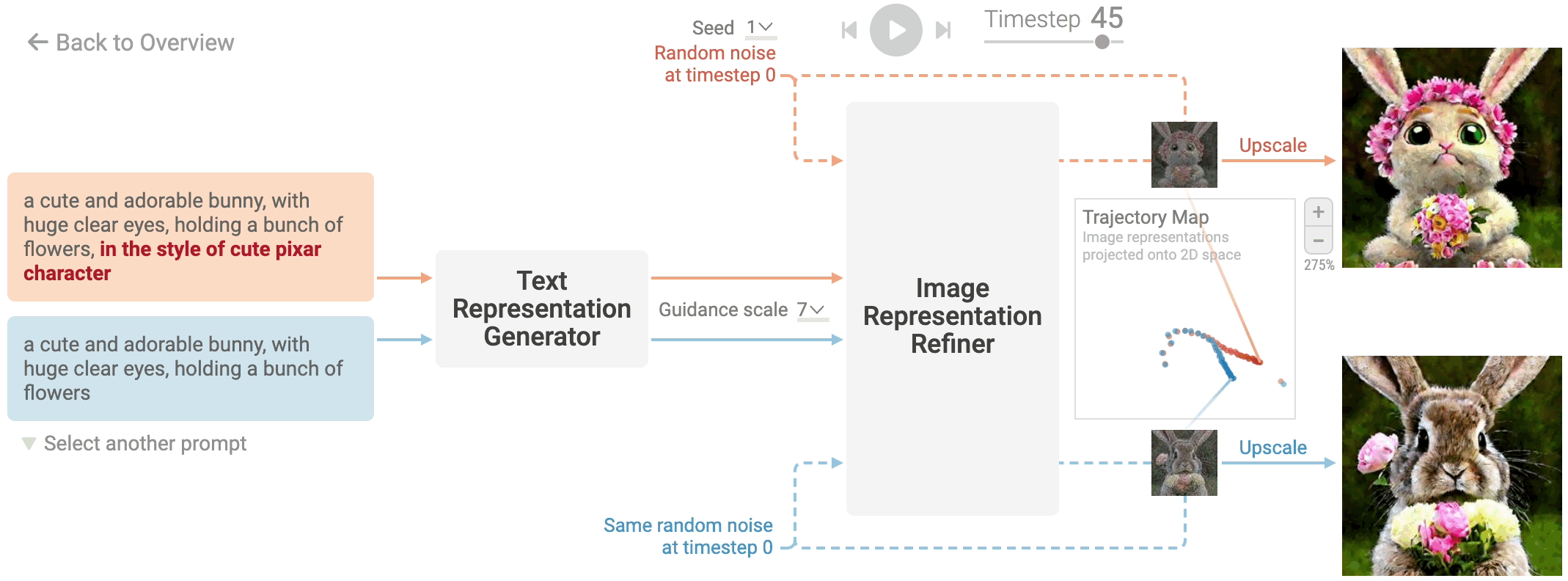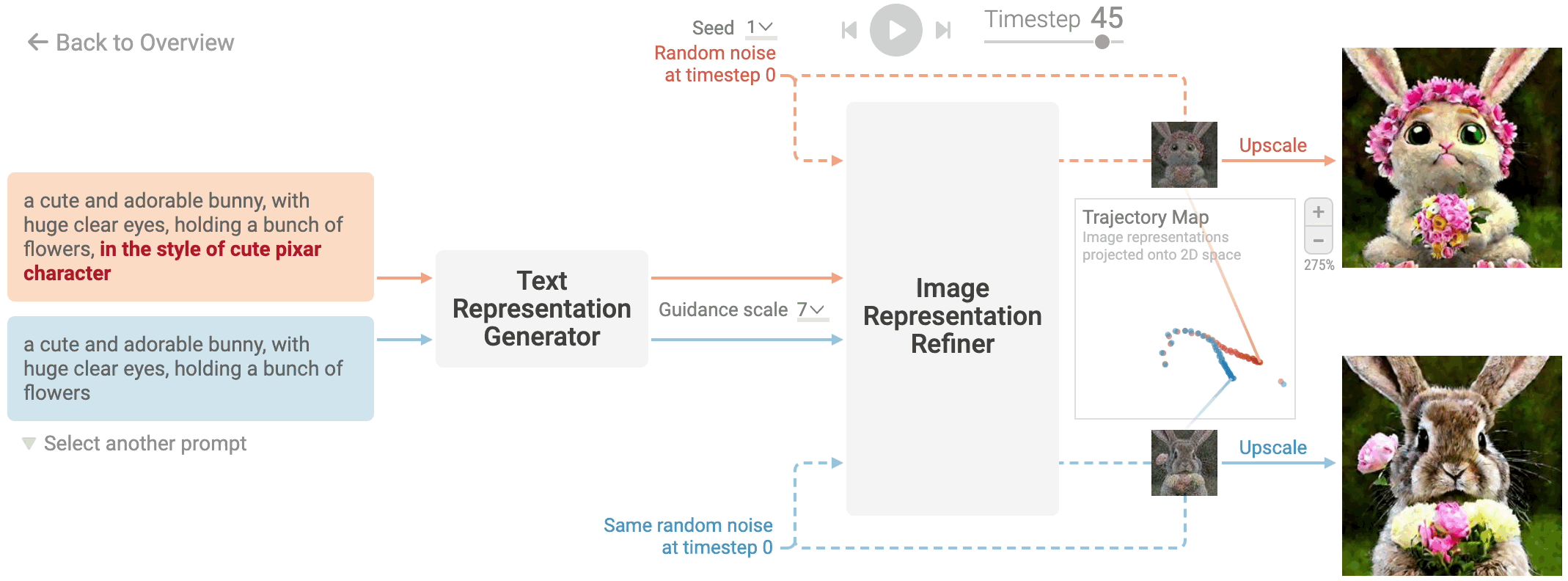
Writing text prompts can be very heuristic and repetitive. For example, starting from the prompt a cute bunny, you should repetitively add and remove keywords such as in the style of cute pixar character, until you reach to the desired image.
Therefore, understanding how prompt keywords affect image generation would be greatly helpful for writing and refining your prompt. Click the keywords highlighted in the text prompt and compare the image generation of the two prompts that differ only in the keywords.
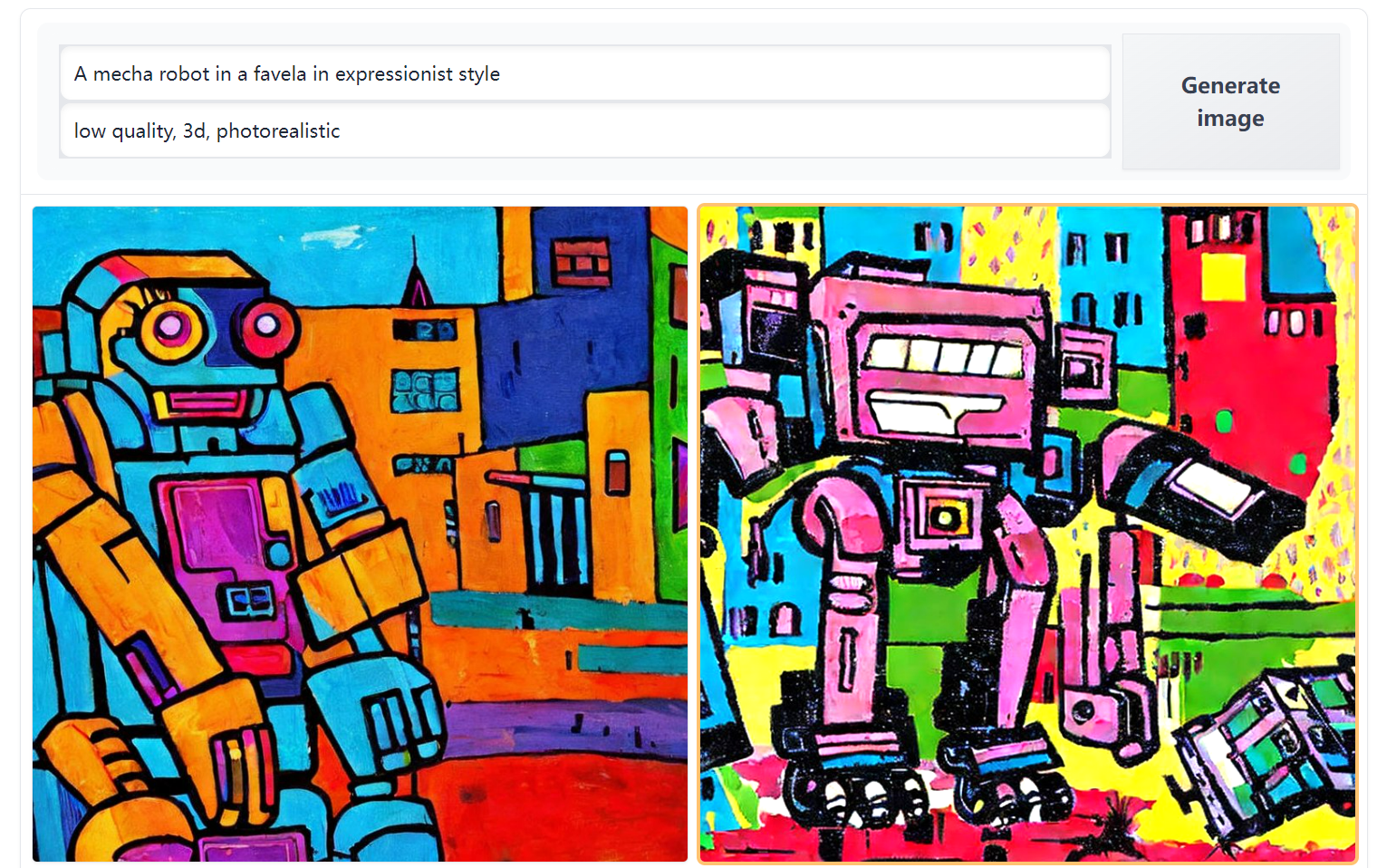
7.8. Stable Diffusion Demo#
Now you can try inputting positive and negative prompts yourself to generate stunning images online.
7.9. Your turn! 🚀#
Assignment - Denoising difussion model
7.10. Acknowledgments#
Thanks to Seongmin Lee for creating the open-source project diffusion-explainer and Jay Alammer for creating the open-source courses The lllustrated Stable Diffusion. They inspire the majority of the content in this chapter.